Curious case of Insert Lock Timeouts
I’ve been a BC dev for a while now. It’s been a learning experience through and through. But there was always an area that I kept pushing away. SQL. I don’t really know why, I never had issues with it, so I guess in my mind I just pushed it away as unimportant. It sat in some distant pile with permissions, tooltips, and translations — my afterthought pile.
This meant I never really understood indexes, database locks, or SIFTs. And I didn’t need to. There are no locking issues when you’re testing with just one user. Well fast forward a few years, and that all had to change.
For the better part of last year, I was working on a project where we were trying to analyze the performance of a huge monolithic app (3k+ objects). There were many sides we tried attacking the problem from, AL Profiler, Telemetry, BCPT,… Ultimately, we decided that our first focus should be on removing locks as the app is planned to be used by 100+ concurrent users and a ton of background services.
We set up BCPT tests, start running them, and find our first batch of deadlocks and lock timeouts.
Time to figure out how locks work. I knew we got ReadIsolation a while ago that supposedly helps with locks. I came across a couple of brilliant blog posts by Alexander Drogin. They helped me understand what locks are and how read isolation changes them. That’s not what I’m going to focus on here, but if you’re interested in that, here are the links: Transaction Isolation in Business Central, ReadCommitted Isolation in Azure SQL, ReadCommittedSnapshotIsolation and the Write Skew Anomaly.
Some changes to read isolation, some missing filters added and some write transactions started later in the process, and we made our first progress. No locks on 100 concurrent users! Okay, add another scenario, rinse, and repeat.
Everything seemed fine for a while until we added 5 or 6 scenarios to run concurrently. Then something extremely weird started happening. We got lock timeouts, but not on reads but on writes. That broke my mind. How am I blocked from inserting a record? I’d get modify, but insert? How can a different transaction meddle with inserts?

“We can’t save your changes right now, because a record in table ‘Simple Entry’ is being updated in a transaction done by another session. You’ll have to wait until the other transaction has completed, which may take a while. Please try again later.”
This is where the call stack breaks:
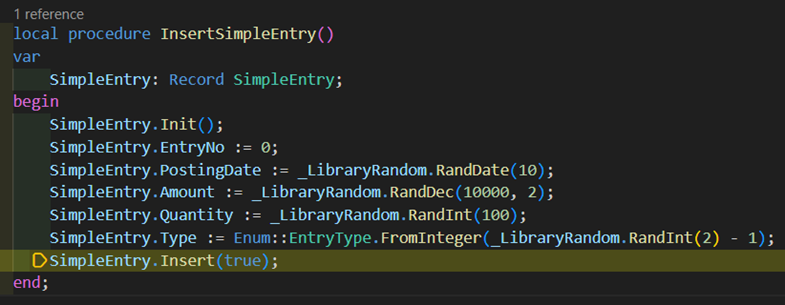
Now you’re probably thinking “Ha! You must have some weird logic on OnInsert trigger or a subscriber!”. Yeah, I thought that too. I removed all trigger, all subscribers, all global database subscribers, and nothing, still the same issue…
The answer was staring me right in the face. Here’s how the locks look after an insert to my SimpleEntry table.

Due to my lack of knowledge of what is SIFT and how it works, my mind dismissed it as “huh, that’s odd, anyway, moving on.”. But seeing the locks enough times, I decided maybe it finally is time to properly learn about SIFT.
If you’re comfortable with understanding SIFT, feel free to skip to the section about SIFT Locks where we continue the lock story. For everyone else, let’s take a detour, and understand what SIFTs are first.
SIFT in a nutshell
SIFT stands for SumIndexField Technology. The documentation could honestly do a better job of explaining the concept. Here’s how it works:
Imagine we have a simple table, like our SimpleEntry table. Nothing special, a primary key, a couple of fields, that’s it.
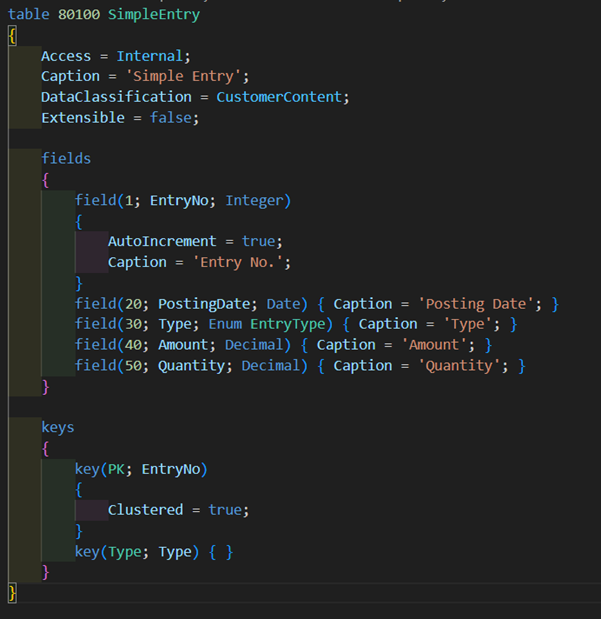
And say we have some data in there:
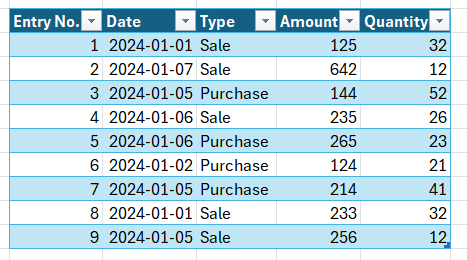
Now let’s say we want to figure out the total amount of sales entries. We’d do something like this:
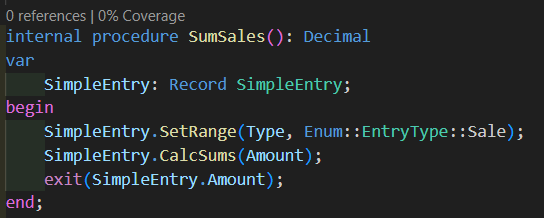
Or also common, something like this

In both cases, the SQL server goes through all lines of type sales and starts calculating 125 + 642 + … = 1491!
But if you define SumIndexFields on a particular key like:
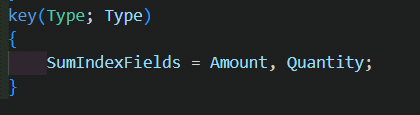
The SQL server will start maintaining something called an Indexed View. You can think of it as another table, where sums for this key are stored. For our example, it would look like this:
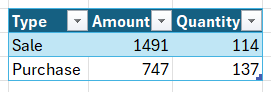
Every time an entry is added or modified in the SimpleEntry table, the sum in this “table” is updated as well. This means that the next time you ask for a total amount of Sale type entries, the SQL server can just go “1491!” without looping through each record.
Turns out SIFT is the culprit!
We mentioned that if SQL maintains an indexed view, it has to update that view for each change in the underlying table. That means, that if I insert a new record into my SimpleEntry table, two rows become locked; the newly created entry record, and the row in the indexed view.
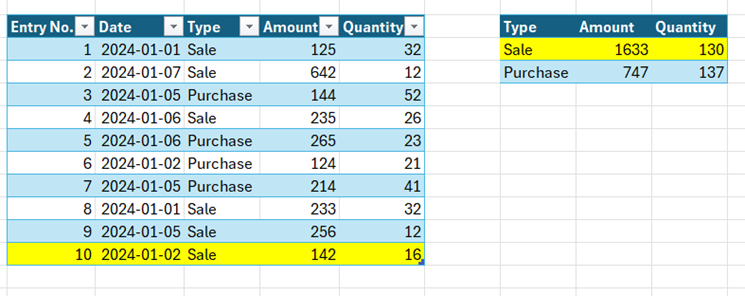
And the lock is held for the duration of the transaction.
If a separate transaction tries to add a record of type Sale to the entry table, that in itself shouldn’t be a problem for the SimpleEntry table. However, as that insert needs to also update the Indexed View, it will have to wait until the first transaction releases the lock on it.
A record of type Purchase however will have no issues, as it doesn’t need the Sale row in the indexed view.
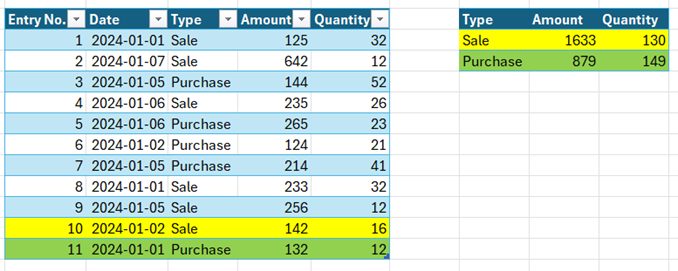
When these transactions pile up, as they do when you have 100 concurrent users, you quickly reach the 10-second limit at which point the waiting transaction times out.
And that’s not the only side that can cause issues. Remember, anytime we lock the related row in the indexed view, we can’t insert a record in the entry table with a matching index value. The two examples above that make use of indexed views, the SumSales procedure and the SalesAmount flow field, are both reading the indexed view. So if they read it with UpdLock, which is the default locking type, after you start a write transaction, you’re going to have a problem. That is until tri-state locking becomes the default. You can read what Duilio Tacconi wrote about it if you’d like to know more.
But until we have tri-state locking, both of these examples will effectively lock the row in our indexed view, and while the locks are held, inserts will have to wait:
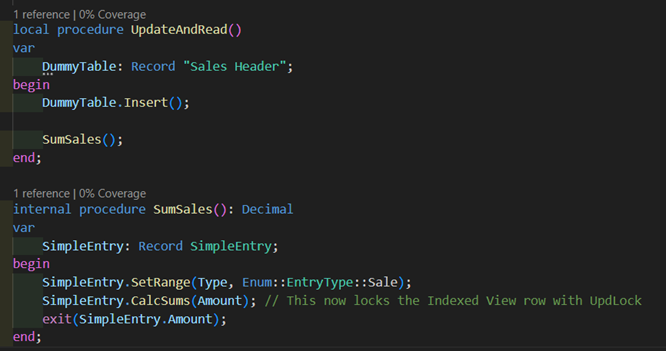
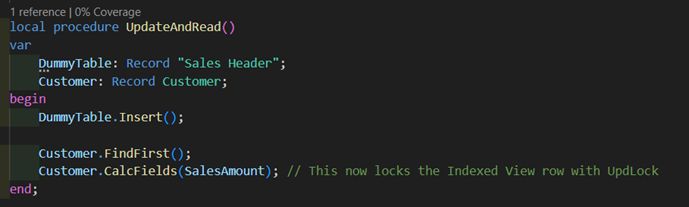
Yes, flow fields also lock rows. They lock them with the same lock type as the parent table. So in the above example, if I’d set the IsolationLevel on the Customer to ReadUncommited, then the flow field would apply this hint as well.
So what should we do about it?
Should we stop using SIFT? No! Well, maybe. Sometimes. It depends. There are a couple of different approaches we took to resolve our insert lockouts.
- Lower read isolation on reads that were reading the indexed view with UpdLock.
- Keep the table as is, change the logic of the process so it inserts in the TempTable first, and only inserts in the actual table at the very end, holding locks for a minimal time.
- Run the processes asynchronously through a job queue entry
- Switch user inserts to a staging table that’s optimized for inserting and have a job transfer data to read optimized tables.
- Remove SumIndexFields and accept the read performance penalty
There’s another one, that we haven’t tried. Just the other day, I was watching Waldo’s Coding 4 Performance session from BC Tech Days where he mentions IncludedFields as an alternative to SIFT. That’s another option to look into.
As you see, it’s not a simple answer, there are different options, all coming with their own set of tradeoffs, but at least I hope the next time you experience issues with locks on inserts, you’ll know where to look.